Codifiche
Vediamo ora come è possibile codificare le informazioni come testi, immagini, audio e video tramite byte.
Convenzionalmente, i byte sono rappresentati sotto forma esadecimale.
- Bit
- Byte
- KB, MB, GB e altre unità di misura
- Codifica di testo ASCII
- Codifica di testo Unicode
- Codifica dei colori RGB
- Codifica di una immagine
- Codifica di un audio
- Codifica di un video
Bit
Si chiama bit qualcosa che può assumere solo valori 0 e 1,
oppure True o False, o altri valori che hanno significato caso per caso,
ad esempio presente o assente in un appello a scuola,
acceso o spento nel caso di una luce o di un dispositivo,
bianco o nero in una scacchiera, presenza di segnale o
assenza di segnale in un circuito elettronico, testa o croce nel lancio
di una moneta e molto altro.
Un valore booleano può quindi essere rappresentato con un bit.
Byte
Un byte è formato da 8 bit ed è l’unità di misura fondamentale dell’informazione.
Calcolando tutte le possibili combinazioni di zero e uno, abbiamo visto che un byte può contenere 256 possibili valori che, convenzionalmente, rappresentano i numeri da 0 a 255 in decimale. Tutti i possibili valori di un byte possono anche essere rappresentati in esadecimale, con i numeri a due cifre esadecimali da 00 a FF.
Oltre ai numeri interi, è possibile rappresentare altro.
Vedremo che con un solo byte è possibile rappresentare una lettera
dell’alfabeto latino, cioè l’alfabeto in comune alle lingue europee,
ad esempio A-Z ma anche minuscole a-z e altri simboli !?+* …
Un byte da solo non è sufficiente a fare molto. Si utilizzano spesso molti più byte messi insieme a formare quantità di informazioni sempre più grandi.
KB, MB, GB e altre unità di misura
Si definiscono quindi le unità di misura nel Sistema Internazionale:
- KB (kilobyte) = 1.000 byte
- MB (megabyte) = 1.000 KB = 1.000.000 byte
- GB (gigabyte) = 1.000 MB = 1.000.000 KB = 1.000.000.000 byte
- TB (terabyte) = 1.000 GB = …
Per motivi tecnici, essendo tutta l’informatica basata sulle potenze del 2, esistono e vengono in realtà usate più spesso delle unità del Sistema Internazionale riportate sopra anche le seguenti unità definite tramite i prefissi binari:
- KiB (kibibyte) = 1.024 byte
- MiB (mebibyte) = 1.024 KiB = 1024² byte
- GiB (gibibyte) = 1.024 MiB = 1024³ byte
- TiB (tebibyte) = 1.024 GiB = …
1.024 è una potenza del 2, cioè 2¹⁰, ed è una cifra più tonda di 1.000 per un computer, mentre 1.000 è una cifra più tonda per un umano.
Nella pratica, nessuno pronuncia mai kibibyte o mebibyte ma sempre kilobyte e megabyte intendendo a volte i multipli di 1.000 a volte i multipli di 1.024, facendo una gran confusione. Se non specificato altrimenti, cioè se non si legge KiB o MiB, bisogna tentare di capire dal contesto quale delle due si intenda.
Sì, si fa una gran confusione.
Codifica di testo ASCII
Vediamo ora come convertire i byte del testo.
Esiste una tabella, chiamata tabella ASCII, che associa a ogni lettera, numero, simbolo un ben determinato byte. Per i caratteri più semplici questa tabella può bastare.
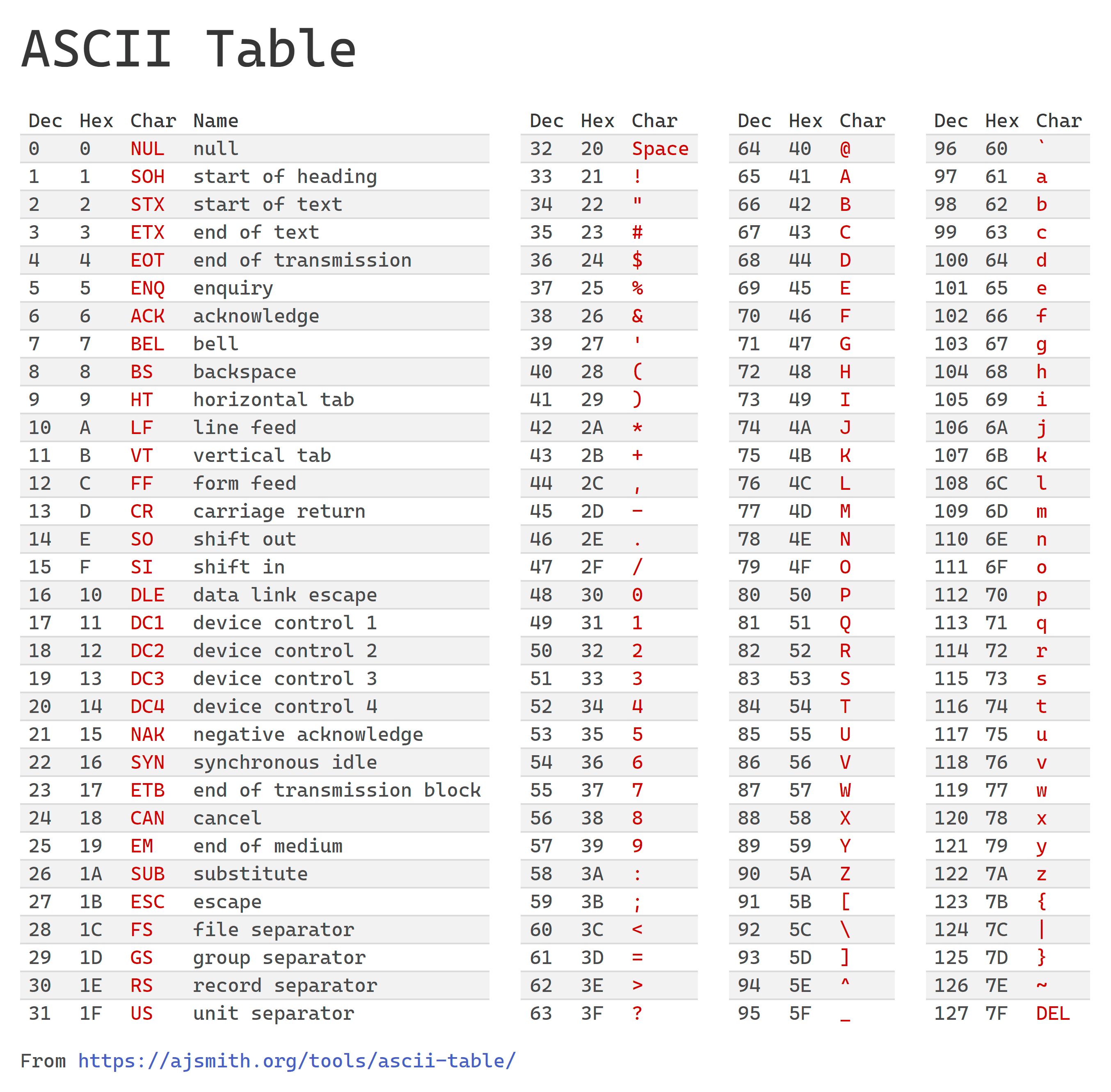
La tabella mostra come codificare alcuni caratteri (in rosso) tramite un singolo
byte, indicato sia come decimale (dec) che esadecimale (hex).
Useremo sempre la rappresentazione esadecimale 😅, quindi per semplicità
tralasceremo il prefisso 0x.
La tabella è divisa in 4 parti:
-
Caratteri da 00 a 1F: non più utilizzati, venivano utilizzati da vecchi terminali e stampanti ad aghi secoli fa. Fanno eccezioni i caratteri CR e LF che servono per codificare l’andata a capo, ad esempio quando si preme invio sulla tastiera.
-
Caratteri da 20 a 3F: alcuni simboli e numeri. Notate il carattere 20 che è il carattere spazio, quello che serve per separare parole e viene inserito premendo spazio sulla tastiera. Non è uno spazio vuoto, è esso stesso un carattere.
-
Caratteri da 40 a 5F: lettere maiuscole.
-
Caratteri da 60 a 7F: lettere minuscole.
La tabella contiene metà dei valori possibili per un byte, cioè 128 caratteri. L’intervallo da 80 a FF non è presente. Esistono tabelle che estendono la tabella ASCII con altri 128 caratteri, ma è una tecnica che non si usa più, soppiantata da Unicode (vedi di seguito).
Il mio nome in ASCII
Codifichiamo il nostro nome in ASCII! Ad esempio Mario Rossi è scritto così:
4D 61 72 69 6F 20 52 6F 73 73 69
Notate il byte 20 usato per codificare lo spazio fra Mario e Rossi. Notate anche il byte 73 ripetuto 2 volte di fila: solo le doppie s di Rossi.
ASCII Art!
Curiosità: mai sentito parlare di ASCII art?
C’è chi disegna immagini usando solo caratteri! Il nome di ASCII Art deriva proprio dalla tabella ASCII.
L’immagine viene da qui.
Ci sono siti che convertono foto in ASCII art. Cercateli con Google.
Codifica di testo Unicode
L’ASCII permette di rappresentare in byte del testo formato da caratteri semplici: lettere maiuscole e minuscole, punteggiatura, parentesi e numeri. Questo è però troppo limitativo, pensate ad esempio alle lettere italiane accentate ÀÈÌÒÙ o con accento É (perché, poiché) ma anche ÄÖÜ in tedesco, caratteri come Ñ in spagnolo, le legature francesi Œ ed Æ o altri alfabeti come il greco, il cirillico usato per russo, ucraino, serbo, bulgaro, … o anche l’arabo (أبجدية عربية), gli alfabeti giapponesi Katakana (片仮名) e Hiragana (平仮名), gli ideogrammi giapponesi Kanji (漢字) e cinesi semplificati (汉语) e tradizionali (漢語) e molti altri caratteri e alfabeti, fino a geroglifici, simboli runici e migliaia di altri casi speciali.
Anche le emoji 😅😂😍👌 sono caratteri!
Il sistema per rappresentare tutti questi caratteri si chiama Unicode ed è usato ormai ovunque in informatica e su Internet.
Unicode è una enorme tabella separata in alfabeti che contiene più di 150.000 caratteri e cresce di anno in anno. Ogni anno si aggiungono nuovi caratteri e emoji.
Alfabeti e caratteri
Ogni carattere (code point secondo la terminologia Unicode) è rappresentato da un codice esadecimale da 4-5 cifre spesso indicato con il prefisso U+. Ecco alcuni caratteri di esempio:
- Ä (U+00C4), ü (U+00FC), Ď (U+010E)
- Δ (U+0394), Ψ (U+03A8), β (U+03B2)
- И (U+0418), ж (U+0436), Я (U+042F)
- 💔 (U+1F494), 🥰 (U+1F970), 🦔 (U+1F994), 🔥 (U+1F525)
L’intera tabella è visibile su questo sito. Le emoji invece si possono esplorare su Emojipedia!
Analizziamo la stringa 💔 perché? 🥹
- Andiamo su unicode.run
- Scriviamo il testo, possiamo fare copia-incolla.
- Verifichiamo che Show Below sia impostato su Hex Code Point.
Vediamo che la stringa contiene i seguenti 11 caratteri:
- U+1F494 BROKEN HEART (💔)
- U+0020 SPACE
- U+0070 LATIN SMALL LETTER P
- U+0065 LATIN SMALL LETTER E
- U+0072 LATIN SMALL LETTER R
- U+0063 LATIN SMALL LETTER C
- U+0068 LATIN SMALL LETTER H
- U+00E9 LATIN SMALL LETTER E WITH ACUTE (é)
- U+003F QUESTION MARK
- U+0020 SPACE
- U+1F979 FACE HOLDING BACK TEARS (🥹)
Speriamo non sia successo nulla di grave.
Codifica UTF-8
Come si codifica un testo che contiene caratteri Unicode in byte? Esistono più sistemi ma quello di gran lunga più utilizzato si chiama UTF-8.
Ogni carattere Unicode, sia semplice che più complesso come una emoji, si converte in byte con una procedura complessa che fa sì che il carattere venga scritto con uno o più bytes.
I caratteri che hanno un corrispondente ASCII utilizzano lo stesso byte usato nella tabella ASCII. I caratteri accentati vengono scritti con 2 byte e spesso alfabeti più complessi e emoji vengono scritti con 2, 3 o anche 4 byte.
Per convertire da testo a sequenza di byte UTF-8 utilizziamo di nuovo il sito unicode.run in quanto le regole di conversione sono troppo complesse per essere applicate a mano.
- Andiamo su unicode.run.
- Scriviamo il testo 💔 perché? 🥹 facendo copia-incolla.
- Impostiamo Show Below a UTF-8.
Vediamo come i caratteri vengono codificati in byte:
- F0 9F 92 94 BROKEN HEART (💔)
- 20 SPACE
- 70 LATIN SMALL LETTER P
- 65 LATIN SMALL LETTER E
- 72 LATIN SMALL LETTER R
- 63 LATIN SMALL LETTER C
- 68 LATIN SMALL LETTER H
- C3 A9 LATIN SMALL LETTER E WITH ACUTE (é)
- 3F QUESTION MARK
- 20 SPACE
- F0 9F A5 B9 FACE HOLDING BACK TEARS (🥹)
Notiamo che:
- I caratteri semplici come lo spazio, il punto interrogativo e le lettere p e r c h sono codificati con un solo byte che corrisponde a quello della tabella ASCII.
- Il carattere é è codificato con 2 byte.
- Le emoji 💔🥹 sono codificate ognuna con 4 byte.
Quindi la stringa 💔 perché? 🥹 formata da 11 caratteri è salvata su file o trasmessa su internet con la sequenza di 18 byte:
F0 9F 92 94 20 70 65 72 63 68 C3 A9 3F 20 F0 9F A5 B9
Attenzione: i byte UTF-8 non corrispondono ai codici dei caratteri Unicode, quelli che iniziano con U+! In un certo senso gli assomigliano ma non sono gli stessi. E se si volesse capire come funziona veramente l’algoritmo di conversione? È spiegato qui.
Codifica dei colori RGB
Possiamo rappresentare i colori con 3 componenti fondamentali:
- Red
- Green
- Blue
Gli schermi elettronici sono composti da pixel, cioè puntini luminosi. Ogni pixel è in realtà composto da 3 subpixel, cioè sotto-pixel, uno rosso, uno verde e uno blu. L’occhio umano non riesce a distinguere questi subpixel se non con una lente di ingrandimento.
![]()
L’occhio umano vede i 3 colori mescolati, e percepisce tutti i colori visibili in quanto ogni colore è il risultato di aver mescolato rosso, verde o blu in combinazioni diverse.

Le componenti RGB sono separate e ognuna può avere un valore che va da 0 a 255, dove con 0 si intende spento e con 255 si intende massima intensità.
Naturalmente i numeri 0 e 255 non sono casuali. Corrispondono in esadecimale ai numeri 00 e FF. Ogni componente di un colore RGB può essere rappresentata con un byte.
Un pixel di uno schermo a colori può essere rappresentato con 3 byte.
I colori si rappresentano con 3 byte separati, es. (10, 9C, EB) oppure la sintassi abbreviata #109CEB, usata molto sul web in quanto è quella dei linguaggi HTML e CSS. Il primo byte è il rosso, il secondo il verde, il terzo il blu.
Alcune combinazioni di colori:
- Rosso + verde = Giallo #FFFF00
- Rosso + blu = Magenta #FF00FF
- Verde + blu = Ciano #00FFFF
- Rosso + verde + blu = Bianco #FFFFFF
Il nero si ottiene non mescolando alcun colore #000000. Tutte le gradazioni intermedie si ottengono mescolando i componenti RGB in quantità diverse, es. #FF8000 è arancione mentre #0080FF è azzurro intenso.
Il grigio si ottiene come via di mezzo fra bianco e nero, cioè con tutti i componenti RGB alla stessa intensità, e anche esso può avere tante gradazioni, es:
- Nero #000000
- Grigio scuro #404040
- Grigio intermedio #808080
- Grigio chiaro #C0C0C0
- Bianco #FFFFFF
Provare di persona usando un sito come RGB Color Picker.
Codifica di una immagine
(in via di pubblicazione)
Codifica di un audio
(in via di pubblicazione)
Codifica di un video
(in via di pubblicazione)